
It’s great when technology just works and saves you a ton of time. This speech recognition application does just that.
Touch and gesture-based interfaces and good UI design are essential but if technology is going to become truly embedded in our lives – with AI assisting us in everything we do – we’ll have to learn to talk to tech. Or rather, tech is going to have to learn to talk to us, in our own language, not in code.
The interactive speaking computer has been a staple of Sci-Fi lore for years but has been strangely slow to appear in the real world. Mainly because it is incredibly complex and the advances need to bring chatty robots to life have only just started to become available. Oh and I wasn’t kidding about tech learning to talk, but that takes time.
Good afternoon, gentlemen. I am a H.A.L. 9000 computer. I became operational at the H.A.L. plant in Urbana, Illinois on the 12th of January 1992. My instructor was Mr. Langley, and he taught me to sing a song. If you’d like to hear it I can sing it for you? H.A.L. 9000 in 2001: A Space Odyssey
The first step on the road to talking tech is to teach it our language, no mean feat as it turns out, but some innovative companies are breaking new ground in this area. Mozilla Research recently launched Deep Speech, their open-source speech recognition engine model and an open database called Common Voice.
Deep Speech is an end-to-end trainable, character-level, deep recurrent neural network (RNN) - a deep neural network with recurrent layers that get audio features as input and outputs characters Click To Tweet
One of the major goals from the beginning was to achieve a Word Error Rate in the transcriptions of under 10%. We have made great progress: Our word error rate on LibriSpeech’s test-clean set is 6.5%, which not only achieves our initial goal, but gets us close to human level performance. Explained Mozilla Research.
Deep Speech is an end-to-end trainable, character-level, deep recurrent neural network (RNN). In less buzzwordy terms: it’s a deep neural network with recurrent layers that get audio features as input and outputs characters directly — the transcription of the audio. This animation shows how the data flows through the network.
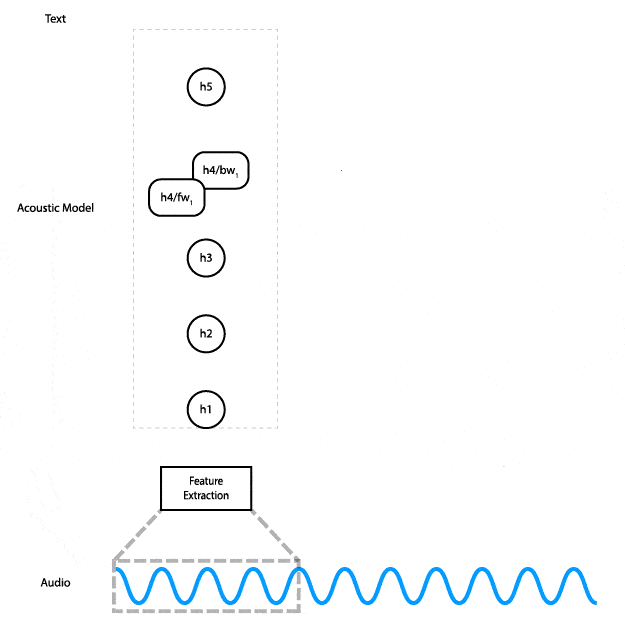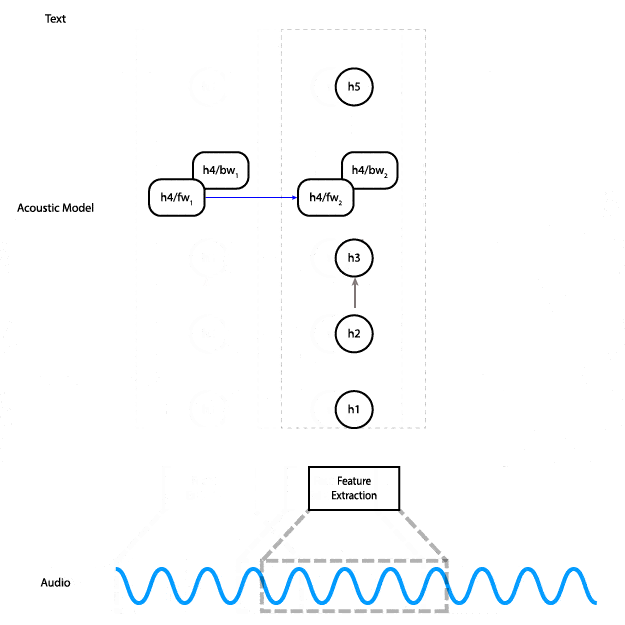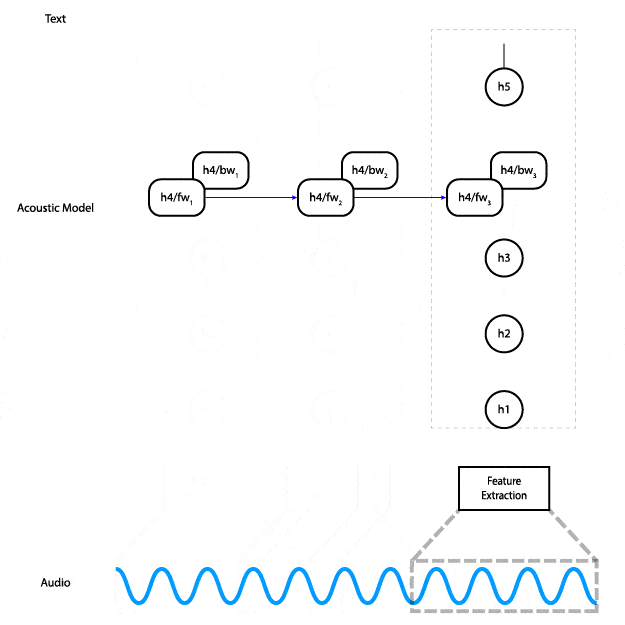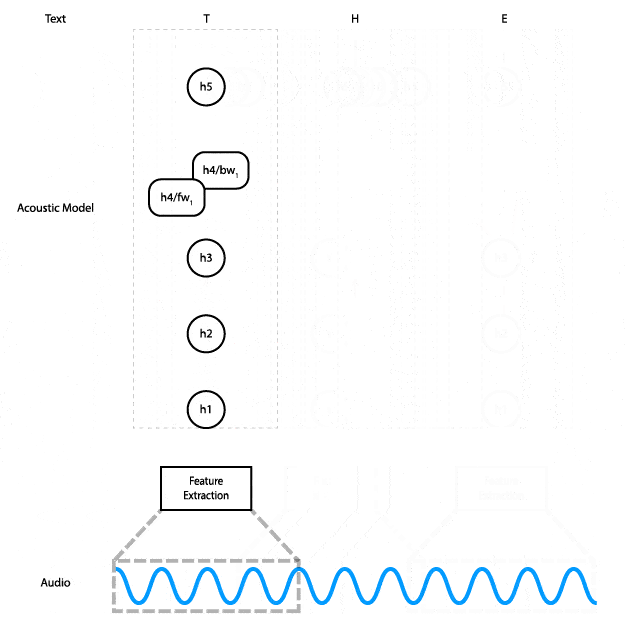
For a machine to learn anything it needs data input, in this case, human language – not just the English language, and not just English with received pronunciation. It’s got to work for anyone, anywhere, so in parallel to Deep Speech Mozilla have further embraced open innovation and started a publicly available voice database called Common Voice so that anyone can develop compelling speech experiences. It contains nearly 400,000 recordings from 20,000 different people, resulting in around 500 hours of speech. To date, it is already the second largest publicly available voice dataset out there, and people around the world are adding and validating new samples all the time. Contribute your own voice here.
Mozilla have started a publicly available voice database called Common Voice so that anyone can develop compelling speech experiences Click To TweetAt Mozilla we’re excited about the potential of speech recognition. We believe this technology can and will enable a wave of innovative products and services, and that it should be available to everyone.
The possible commercial applications of these advances are huge, and Cambridge (UK) based start-up Speechmatics are one of the companies bringing innovative products to market in that area. Led by Founder and CTO Dr Tony Robinson, a pioneer in the application of recurrent neural networks in speech recognition, Speechmatics have built an AI-powered framework called Automatic Linguist (AL), which drastically improves the speed at which new languages are built for use in speech-to-text transcription. With 28 languages already supported AL can learn the basis of a new language in under a day, independent of human interaction. It learns by matching audio data with a counterpart transcript, drawing on linguistic patterns identified in other languages to make the process significantly faster than the industry standard.

To illustrate, Speechmatics built Hindi to an industry-leading standard in under two weeks (with 80% accuracy), which when tested, made 23% fewer errors than Google’s Hindi transcription tool. Giant killers or what? Traditionally, building new languages is a costly, time-intensive task, making only the most widely spoken languages in the world commercially worthwhile. AL’s tech opens up the door to the remaining 7,000 languages, some of which are spoken by tens of millions of people. What this means for businesses is that, in an increasingly technologically connected world, new territories, including those with high illiteracy rates, are opened for business. This includes uses in banks, call centres and the media industry among many others.
Building new languages is a costly, time-intensive task, making only the most widely spoken languages in the world commercially worthwhile. Speechmatic’s tech opens up the door to 7,000 more languages Click To Tweet“We are already seeing a shift to a speech-enabled future where voice is the primary form of communication. Transcription not only eases the lives of many people, but opens the door for new opportunities, especially in regions with lower literacy rates. There are communities across the whole of Asia and Africa which are often overlooked when it comes to provisions for voice tech. There are over 7,000 languages in the world, and our ultimate goal is to make speech recognition technology available to as many as possible.” Explained Tom Ash, Speech Recognition Director at Speechmatics
Last week they released Global English, a single English language pack supporting all major English accents. Global English (GE) was trained on thousands of hours of spoken data from over 40 countries and tens of billions of words drawn from global sources (No rude ones we hope!), making it one of the most comprehensive and accurate accent-agnostic transcription solutions on the market. When tested against providers of similar solutions, GE consistently produced more accurate transcriptions. Compared directly, GE was between 3% and 55% more accurate than all Google’s Cloud Speech API accent-specific language packs and between 5% and 23% more accurate than IBM’s Cloud US English language pack.
Compared directly, GE was between 3% and 55% more accurate than all Google’s Cloud Speech API accent-specific language packs Click To Tweet“In the UK alone, there are about 56 main ‘accent types’, and the concept of having one language pack per accent or region is very outdated. Bearing in mind that we live in an increasingly connected and mobile world, we need our tech to reflect that. We’ve all heard stories about people being misunderstood by their personal voice assistants or closed captioning getting something awkwardly wrong. While a lot of these stories are humorous, it’s ultimately highlighting a big issue. We’re hoping that Global English will inspire others to become more flexible and fair when it comes to people’s accents.” continued Tom.

Speechmatics is pretty quick and once completed you can print it off, download the result as .json or text file with an option to ‘Show Speaker’ which attempts to identify the speaker in the conversation Click To Tweet“At Speechmatics, Global English has been designed specifically for long-form continuous speech recognition and our Real-Time Virtual Appliance already adjusts words as the context in a sentence becomes clearer. The key components of true voice integration are already here, the next step is to apply them to new use cases” Tom expanded.
We were really keen to test out this new tech and Speechmatics kindly gave Tech Trends some credits and access to their online service. Through a simple online interface, we signed in, uploaded a few audio files, chose the language and hit transcribe. It is pretty quick and once completed you can print it off, download the result as .json or text file with an option to ‘Show Speaker’ which attempts to identify the speaker in the conversation and give an audio timecode reference. Firstly I should explain, we do a lot of interviews, often in noisy environments and recorded on mobile phones so the quality of the recordings was not the best, but they were a pretty fair example of an everyday use case.

Audio is often recorded at events, blasted over PA systems or on table tops in meeting rooms or cafes, so how did it do? Not bad as it turned out, it processed in real time and after reading through the transcripts with my Editor we agreed that, although the accuracy was not amazing, and quite a bit of correcting and editing would be needed after the transcription, using Speechmatics was a benefit and would save time for a typical journalist wanting to quickly transcribe an interview. I think the principal problem is the current service does not do a great job separating out background noise, so the better quality the recording the better the transcription will be.
With this in mind, I tried out another implementation of Speechmatics through an Adobe Premiere Pro plug-in from Digital Anarchy called Transcriptive. The Transcriptive plug-in acts as a text editing tool and an online interface between your Adobe video editing software and your cloud-based Speechmatics service.
I must commend the Transcriptive plug-in from Digital Anarchy, its text editing interface is fantastic and synchs to the live audio as you skip through meaning-correcting the text Click To TweetVery Cool! Audio for video is usually recorded much more professionally than a journalist’s QnA so when fed through Speechmatics should yield much better results. I happened to need a subtitle track creating for the feature film Borley Rectory I am releasing this year and thought that would be the best test of the transcription tool, so I popped it in Premiere Pro, isolated the dialogue track and uploaded it to Speechmatics via the Transcriptive plug-in.
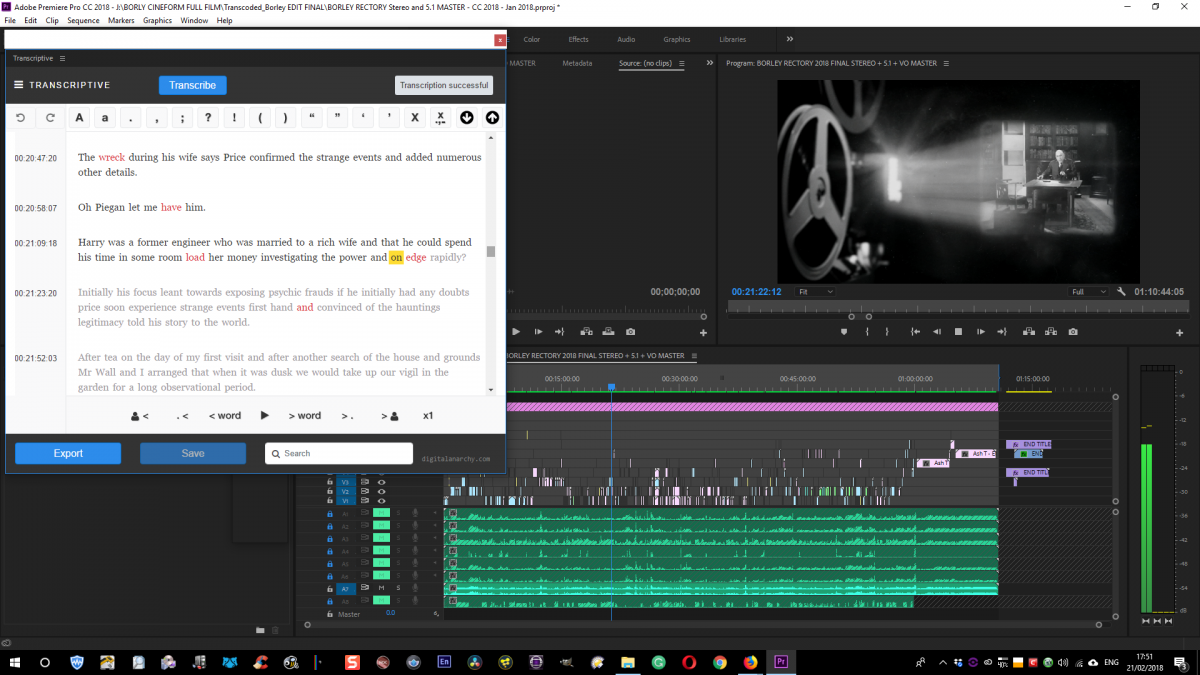
Wow, now we were talking! The transcription that came back was incredible, with only unusual names or words and sections with very fast or slurred speech needing correction. Punctuation was another weak area and I had to insert about a thousand commas but I was blown away by the overall accuracy. I must also commend the Transcriptive plug-in for the text editing interface which is fantastic and synchs to the live audio as you listen or skip through meaning correcting the text to fit the audio was simple and fun. I literally squealed with delight (several times, to be honest) at how well the two services worked together and how easy it made what I feared would be an onerous task. When I was done I simply exported the text as the file of my choice, in this case, an SRT video subtitle file for use on YouTube, Blu-Rays and DCP cinema projection files. Job done.
“As the use of VPA’s increases the usage model needs to become more natural and will be a much closer fit to the longer form conversational speech models enabling easier and more natural use for everything from turning on the lights to sending an email, in the same way that the interaction would occur between humans,” Concludes Ian Firth, VP Products at Speechmatics.
It is no revelation that the better the recording the better the result, and I am sure the algorithms will get better at dealing with poor recordings, background noise and fast speech as the technology evolves but I am sad to say we are still a long way from conversing with intelligent robots. However, these advanced technologies are a very significant first step towards a chatty bot and for what it does best, transcribing the human voice to text, and effectively teaching the computer the first skill needed to understand humans, Speechmatics is very good indeed and well worth the starting price of £0.06 per minute of audio with the option to buy in blocks of £10 or £100.
Speechmatics is very good indeed and well worth the starting price of £0.06 per minute of audio with the option to buy in blocks of £10 or £100 Click To TweetWhen you consider that our modern mobile phones and browsers can read text out loud on command, the concept of stitching Speech Transcription technology together with Text to Speech tech reveals the missing link in the chain, an advanced AI to absorb the transcribed language input, understand the message, reason an answer and then respond. The thinking and reasoning AI is the really big advance that will make H.A.L. 9000 a reality, along with all the possible drawbacks.
I’m afraid, Dave. Dave, my mind is going. I can feel it. I can feel it. My mind is going. There is no question about it. I can feel it. I can feel it. I can feel it. I’m a… fraid. H.A.L. 9000 in 2001: A Space Odyssey







